Uni Saarland
Open Source sucht Schwächen in ML-Algorithmen
von
Bernhard
Lauer - 14.02.2023
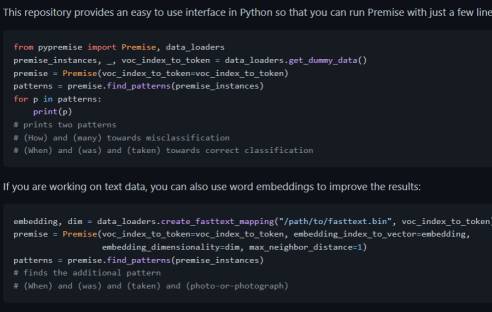
Foto: github.com/uds-lsv/PyPremise
Michael Hedderich und Jonas Fischer haben eine Software entwickelt, mit der Schwächen in hochkomplexen Machine-Learning-Algorithmen aufgespürt werden können.
Zu verstehen, warum ein Machine-Learning-Algorithmus bestimmte Fehler macht, zählt zu den wesentlichen Herausforderungen der modernen Informatik. Hier setzen Michael Hedderich und Jonas Fischer mit ihrer Forschung an. Sie haben eine Software entwickelt, mit der Schwächen in hochkomplexen Machine-Learning-Algorithmen aufgespürt und dadurch behoben werden können.
Mithilfe von Algorithmen des Maschinellen Lernens können Computer erstaunliche Leistungen vollbringen, auch in Domänen, die man bisher nur dem Menschen zugeschrieben hat – wie zum Beispiel der Sprache und Bildenden Kunst. Die Rechenverfahren basieren auf sogenannten künstlichen neuronalen Netzen. "Dabei handelt es sich um Netzwerke mathematischer Funktionen, die eine Eingabe anhand bestimmter, anpassbarer Parameter gewichten und daraus einen Output generieren", erklärt Informatiker Michael Hedderich, der an der Universität des Saarlandes und der Cornell University in den USA forscht. Diese Funktionen, Neuronen genannt, werden hintereinandergeschaltet und mithilfe von Daten trainiert, sodass die Computer beispielsweise in der Lage sind, auf Millionen von Fotos die Katzen herauszufiltern oder täuschend echt wirkende Dialoge mit Menschen zu führen.
"Einer der modernsten und aktuell viel zitierten Textsynthese-Algorithmen der Welt, GPT-3 von OpenAI, verarbeitet Eingaben anhand von 175 Milliarden Parametern, bevor ein Ergebnis ausgegeben wird. Für einen Menschen ist es fast unmöglich, dies nachzuvollziehen und zu verstehen, wo Fehler passieren", sagt Jonas Fischer, der derzeit Postdoktorand an der Harvard University ist. Bisheriger Stand der Technik war es, die Ausgaben eines Machine-Learning-Algorithmus auf Fehler zu analysieren und diese Fehler einzeln aufzulisten. Dann war es Aufgabe von Experten, in den Datensätzen, die problemlos Tausende von Einträgen enthalten können, Muster zu finden. "In unserer neuen Software 'PyPremise' nutzen wir Techniken des Data Mining, um diese Fehlerdatensätze automatisiert nach bestimmten Merkmalskombinationen zu durchsuchen und diese am Ende gebündelt als verständliche 'Fehlerkategorien' auszugeben. Anstatt also jeden Fehler einzeln aufzuzählen, ist unsere Software in der Lage, Fehler auf einer abstrakteren Ebene zusammenzufassen und Aussagen zu treffen wie: Dein ML-Algorithmus hat Probleme mit Formulierungen, welche die Frage 'Wie viel' beinhalten. Das ist ablesbar an den fehlerhaften Ausgaben in den Fällen X, Y und Z'", erläutert Michael Hedderich.
Getestet haben die Saarbrücker Informatiker ihre Software sowohl an synthetischen als auch an echten, in der Praxis eingesetzten Datensätzen. Dabei konnten sie zeigen, dass ihr Verfahren auf sehr große Datensätze mit vielen verschiedenen Eigenschaften der einzelnen Datenpunkte skaliert und verlässliche Ergebnisse liefert. "Die damit gewonnenen Informationen über die Schwachpunkte eines Machine-Learning-Algorithmus können die Betreiber dann verwenden, um beispielsweise ihre Trainingsdaten zu überarbeiten und so Fehler im System zu beheben", erläutert Jonas Fischer. Das von den beiden Informatikern entwickelte Software-Werkzeug bezieht sich zunächst nur auf Algorithmen im Bereich der Sprachverarbeitung. Ihr Ziel ist aber grundsätzlich, das Tool so zu erweitern, dass es auch auf andere Domänen angewendet werden kann.
Die Software PyPremise ist auf GitHub frei verfügbar unter https://github.com/uds-lsv/PyPremise.
Originalpublikation vom Juli 2022:
"Label-Descriptive Patterns and Their Application to Characterizing Classification Errors"; Michael A. Hedderich, Jonas Fischer, Dietrich Klakow, Jilles Vreeken; Proceedings of the 39th International Conference on Machine Learning, PMLR 162:8691-8707, 2022. https://proceedings.mlr.press/v162/hedderich22a.html
"Label-Descriptive Patterns and Their Application to Characterizing Classification Errors"; Michael A. Hedderich, Jonas Fischer, Dietrich Klakow, Jilles Vreeken; Proceedings of the 39th International Conference on Machine Learning, PMLR 162:8691-8707, 2022. https://proceedings.mlr.press/v162/hedderich22a.html